BLOG
Streaming Big Data ETL with Impetus Gathr and Syncsort DMX – Guest Blog
Streaming Big Data ETL with Impetus Gathr and Syncsort
Today we are announcing a partnership between Syncsort and Impetus Technologies, and our entry into an integration of batch processing and real-time stream processing that we call “Streaming ETL”. The mix of batch and real-time processing has also been referred to as the Lambda Architecture. Streaming ETL allows a mixing of the best batch and streaming technologies under the umbrella of tools which abstract the complexity of the underlying platforms.
The huge increase in types and sources of data has placed pressure on companies to blend and summarize that data quickly to create actionable information. A combination of real time and batch processing is needed to meet the new demands.
There’s a grab bag of technologies that excel in specific aspects: Hadoop Mapreduce, Storm and Spark for massively parallel processing; Kafka and Spark Streaming along with traditional messaging and queuing software for real time data movement; Mesos and YARN for cluster management. These components can be mixed and matched, but there are many APIs to learn and different skill sets needed to leverage them well.
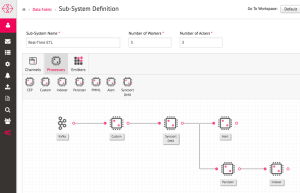
Gathr definition with Syncsort DMX bolt
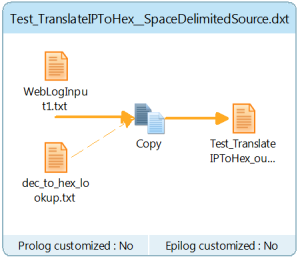
DMX task that performs lookup for IP
Syncsort and Impetus Technologies abstract away the complexity
Impetus Technologies developed Gathr to ease the process of building, deploying and monitoring real-time Big Data applications. Gathr provides an abstraction over the complex technologies used in Big Data platforms (like Storm and Kafka).
Syncsort DMX-h gives users an easy way to specify data transformations and data enrichment, and provides an extremely efficient, high performance run time engine. We have provided this engine to be used in Gathr streaming pipelines. The DMX engine is called whenever the user needs to transform or enrich the data.
Common use cases for Streaming ETL
- A clickstream analyst requires an IP address in a web log to be converted to a decimal or hexadecimal value for downstream processing
- A mobile app sends a product identifier used on a web retail site, and that identifier has to be transformed to the product ID used in the Enterprise Data Warehouse using a lookup
- A hardware manufacturer sends real time testing data from many sites, which needs to be correlated with historical data
On the Syncsort side, we made only minor adjustments to enable the DMX run time engine to allocate less memory than it does for large batch operations, and to expose a Java interface to integrate with Gathr. The Impetus engineering team quickly added a component in their excellent Web UI to allow users to add one or more DMX transformations in any stream. The teams worked together to publish and interpret metadata from the two products. In the coming months, we will be working to add features and enhance the integration.
I will be producing a screencast of this new Streaming ETL software, and both web sites will have more information about this exciting joint solution. We look forward to hearing from you with any questions and feedback.
Table of Contents
MEET GATHR

Turn raw data into business outcomes, at scale and 50x faster
-
Ingestion
-
ETL
-
CDC
-
DQM
-
ML
-
Insights
-
Atomation
-
Xops
-
Business Apps
Recent Posts
View more postsBlog

Blog

Blog

Blog