

BLOG
Move away from batch ETL with next-gen Change Data Capture
As data volumes continue to grow, enterprises are constantly looking for ways to reduce processing time and expedite insight extraction. However, with traditional databases and batch ETL processes, performing analytical queries on huge volumes of data is time-consuming, complex, and cost intensive.
Change Data Capture helps expedite data analysis and integration by providing the flexibility to process only the new data through a smart data architecture, thus incrementally computing updates without modifying or slowing down source systems. This enables enterprises to reduce overheads, improve hardware lifetime, and ensure timely data processing without facing the limitations of batch processing.
That probably sounds like an oversimplified solution to a very complex problem. So, let’s break it down.
Data extraction is integral to data warehousing and data is often extracted on a scheduled basis in bulk and transported to the data warehouse. Typically, all the data in the data warehouse is refreshed with data extracted from the source system. However, an entire refresh involves the extraction and transportation of huge volumes of data and is very expensive in both resources and time. This is where Change Data Capture plays an important role by replicating data in a big data lake with incremental computing updates without modifying or slowing down source systems.
This makes it easy to structure and organize change data from enterprise databases to provide instant insights. Gathr allows you to ingest, blend, and process high velocity big data streams as they arrive, run machine learning models, and train and refresh models in real-time or in batch mode. There are two parts to a Change Data Capture solution with Gathr :
1. One-time load from source tables to the big data lake
To achieve the ‘one-time load’ of all source tables into the big data lake, Gathr Batch jobs on Apache Spark can be built for the purpose. Gathr Batch supports bulk read from any JDBC compliant database and perform ETL/Data Validation checks on the records before writing into the big data lake (see example pipeline below).
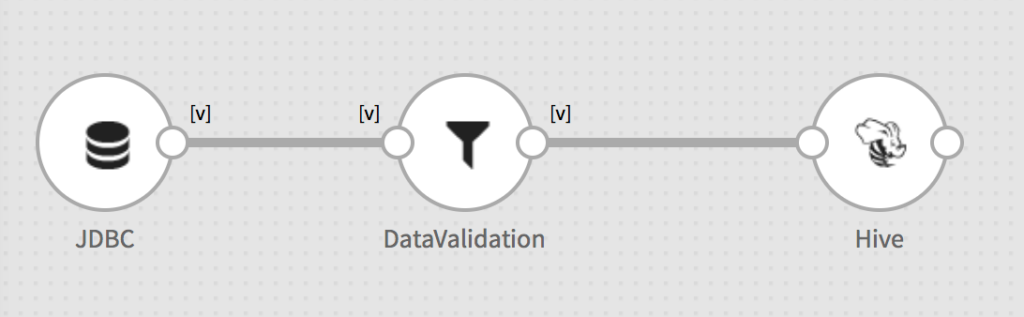
Image 1: A one-time load Gathr batch pipeline
One of the unique features of Gathr, ‘Templates’, allows a user to create a template pipeline (as shown above) and replicate it (create instances) for multiple source tables with a few clicks. This increases the productivity significantly without the need to write/manage hundreds of pipelines, one for each source table.
There are a few phases involved in an end-to-end Change Data Capture implementation:
- Capture the change data in real-time
- Perform any data quality/validation on the change data
- Merge the CDC data into the lake via:
- Running ACID Hive queries
- Land the change data into a staging zone (HDFS) and run reconciliation jobs

Image 2: Phases of a complete CDC solution
2. Real-time synchronization of Change Data Capture events into the big data lake
To capture the change data in real-time, there are more ways. Let’s look at two more popular approaches:
LogMiner approach for Oracle database
In Oracle database, all changes made to user data or to the database dictionary are recorded in the Oracle redo log files. Since LogMiner provides a well-defined, easy-to-use, and comprehensive relational interface to redo log files, it can be used as a tool for capturing change data in near real-time.
To run LogMiner, it requires an open database in ArchiveLog mode with archiving enabled. Also, by default the redo log files do not contain all the necessary information required to construct a CDC record. To log the required information in the redo log files, at the minimum ‘primary key’ or ‘identification key’ must be enabled for supplemental logging for every table of interest.
Gathr and LogMiner
Gathr has the capability to read CDC data from Oracle using LogMiner approach. Gathr agent will capture CDC records and stream them in near real-time into Kafka. Once these events are in kafka, the Gathr streaming application will read them and load it into a staging area in HDFS (as external HIVE source table) after performing any ETL/enrichment/validations etc.
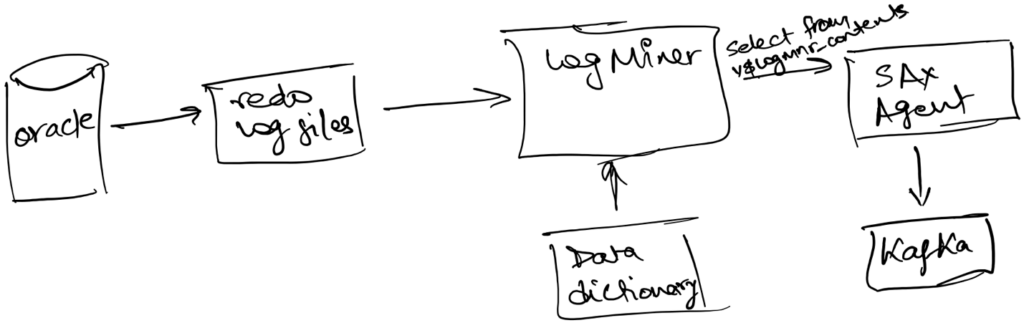
Image 3: Gathr agent capturing events from Log Miner and streaming it into Kafka
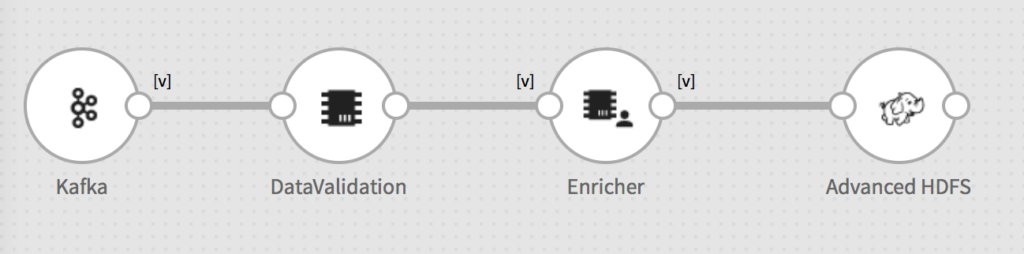
Image 4: Streaming pipeline reading CDC events and landing it into staging area
A Gathr batch job subsequently runs the ACID hive merge queries to update the master table at a periodic interval. Gathr scheduling capabilities help schedule the batch job to run every so often.
Third party CDC software/agent
An alternate option to LogMiner is leveraging other commercial products to capture the change data events in real-time. Attunity is one such product that we have used in the past. Gathr has built-in connectors to read the data from Attunity. We receive two streams from attunity: the metadata about the tables and the change data as it occurs. Once Gathr reads the change data events, it lands it into the staging zone from where the batch pipeline runs the Hive ACID transaction queries to update the master table.
Why implement a CDC solution?
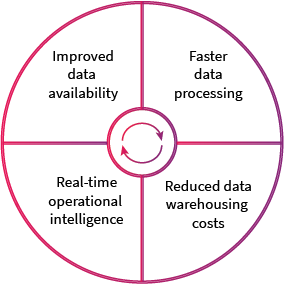
Image 5: Four reasons to implement a CDC
Synchronizing data between systems has always been a massive undertaking. While Change Data Capture makes it easy by letting you know what to do on the destination before the data even leaves the source, it’s important to call out its key benefits. Change Data Capture allows you to:
- Use commodity big data hardware and avoid redundant data replication and delivery
- Improve operational efficiency with real-time change data capture from transactional systems
- Enable real-time data synchronization across the organization
- Eliminate the need for batch windows by replacing bulk load updates with continuous streaming

Table of Contents
MEET GATHR

Turn raw data into business outcomes, at scale and 50x faster
-
Ingestion
-
ETL
-
CDC
-
DQM
-
ML
-
Insights
-
Atomation
-
Xops
-
Business Apps
Recent Posts
View more postsBlog

Blog

Blog
Blog
