BLOG
Data wrangling vs. data cleansing vs. ETL vs. ELT: Understanding key differences
With the growing complexity of analytics use cases, businesses are scrambling to derive actionable insights from unprecedented volumes of data pouring in from multiple sources. As the cloud landscape evolves rapidly, IT teams are under immense pressure to modernize their data management infrastructure and simplify time-consuming processes. As a result, there is a pressing need to deliver clean, accurate, and complete data at lightning speed for multiple analytics use cases.
Data preparation remains a major focus area, as it lays the foundation for advanced analytics. However, within data preparation, terms like data cleansing and data wrangling are often used interchangeably due to certain similarities. Some of the steps involved in these processes also overlap with ETL (extract, transform, load), leading to further confusion. Let’s take a closer look at the differences in these three processes and understand how each can help you maximize the potential of your data.
Data wrangling
The process of translating and mapping data from one raw format to another is called data wrangling (or data munging). Raw data collected from various sources is often unstructured and in different formats, which cannot be used as-is. Data wrangling helps prepare the data and make it usable for further analysis, visualization, model building, and other use cases. Data wrangling usually involves the following steps:
- Identifying and acquiring data from various enterprise sources
- Combining the data for further use and analysis
- Redesigning the data into a usable, functional format
Data wrangling helps unify datasets and enhances their usability by converting them into a format compatible with the target system.
Data cleansing
Data cleansing is the process of identifying and removing or modifying data that is erroneous, incomplete, irrelevant, or duplicate. It eliminates discrepancies in a dataset while preserving the relevant data needed for insights. Data cleansing includes fixing spelling and syntax errors, standardizing datasets, repairing structural issues, correcting empty fields, missing codes, etc. It typically involves the following steps:
- Profiling data to identify quality concerns
- Removing duplicate or irrelevant records
- Rectifying structural errors
- Navigating missing data and null values
- Validating the cleaned data
Data cleansing makes space for new data and enhances the accuracy of a dataset without necessarily deleting information.
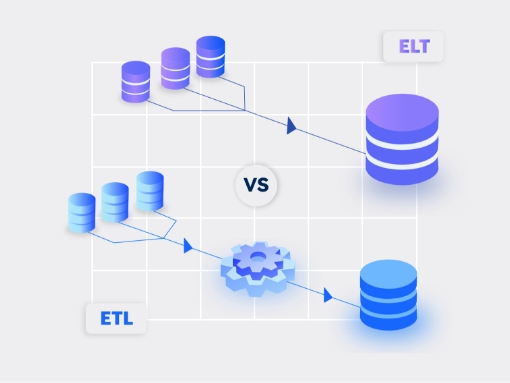
ETL vs. ELT
ETL is a data integration process that integrates data from multiple sources into a single, standardized data store. It lands this into a data warehouse, data lake, or any other target destination. Here are the steps involved in ETL:
- Extract: Extracting data from multiple sources and connectors
- Transform: Transforming the data into a format that matches the planned destination
- Load: Loading the transformed data into the target destination to be used for reporting and other use cases
ETL forms the cornerstone of analytics and machine learning workflows. Leveraging pre-defined business rules, ETL helps clean and organize data in a way that meets specific business intelligence needs. It helps businesses combine structured and unstructured data and provides a single source of truth for better analysis and reporting.
In the past decade, ETL tools have evolved significantly to keep up with the ever-growing volumes and velocity of data. However, as more and more businesses shift to a cloud-based or hybrid data architecture, ETL is now giving way to the new paradigm of ELT, which follows a different order of operations:
- Extract: Extract data from multiple sources and connectors
- Load: Load the data as-is into the cloud data warehouse
- Transform: Transform it leveraging the power and scalability of the target cloud platform
While both processes are similar, each has its advantages and disadvantages. ELT is especially useful for high volume, unstructured datasets as loading occurs directly from the source. ELT does not require too much upfront planning for data extraction and storage. ETL, on the other hand, requires more planning at the onset. Specific data points need to be identified for extraction and business rules need to be created for data transformation. For enterprises with on-premises infrastructure and a small number of data sources, ETL is often a cost-effective strategy. However, for organizations with cloud-based/hybrid infrastructure, massive volumes of data, and multiple sources, ELT is fast becoming the preferred choice.
According to Gartner1, manual data management tasks will decrease by 45% through 2022 with the addition of ML and automated service-level management. Modern data platforms like Gathr can help businesses automate tedious processes and accelerate their data engineering use cases – including ETL, ELT, Reverse ETL, CDC, DQM, and more. To learn more, start your free 14-day trial today!
Table of Contents
MEET GATHR

Turn raw data into business outcomes, at scale and 50x faster
-
Ingestion
-
ETL
-
CDC
-
DQM
-
ML
-
Insights
-
Atomation
-
Xops
-
Business Apps
Recent Posts
View more postsBlog

Blog

Blog

Blog