

Customers
Trusted by the largest enterprises on the planet
WHITEPAPER
Build & Operationalize Machine Learning models
Learn how to leverage machine learning for a competitive advantage
Download Now
Benefits
Streamline the end-to-end ML lifecycle
Use Gathr’s self-service, visual canvas to easily build, train, and deploy complex models. Select from the platform’s 300+ built-in operators to create models faster than ever before.
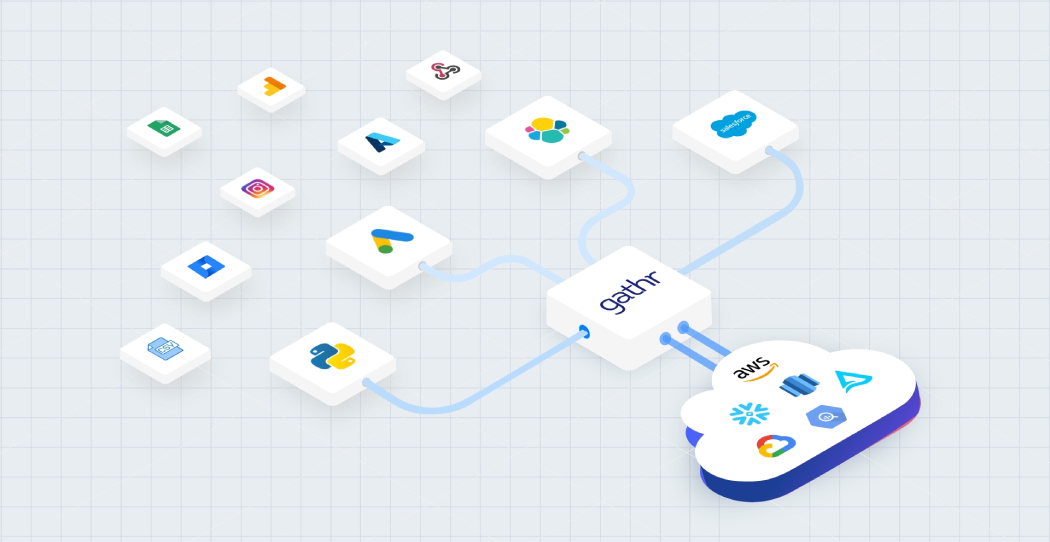
Import from your favorite tools
Import ML models from platforms like TensorFlow and Scikit-learn. Get complete support for multiple algorithms for classification, clustering, and regression analysis.

Train and score models efficiently
Train models on curated datasets and build streaming pipelines for model scoring in real-time. Optimize model hyper-parameters to maximize performance.

Get deployment flexibility
Easily distribute your models on a Spark cluster for linear scalability. You can also use Kubernetes to scale models that you want to expose as a REST endpoint.

Leverage model-as-a-service
Once built, migrate your stand-alone data science models to an application exposed as a REST service for use across teams and use cases.
Webinar
Anomaly Detection with Machine Learning at Scale
Watch Webinar
MEET GATHR
One-of-a-kind no-code, unified
data-to-outcome platform
- No-code for data at scale, batch and streaming
- Gen AI help to search, understand, query, and build easily
- 250+ connectors,
200+ operators,
50+ apps and
solution blueprints - Unified collaborative experience
- Best of open source and enterprise grade
- Production ready output from day 1
Capabilities
 Data integration
Data integration  Machine
Machine  Action
Action  Workflow & business process automation
Workflow & business process automation
 Business
Business Customers Speak
Trusted by business leaders
Leading Multinational Bank
![]()
Gathr has brought all our data scientists on a single platform to design, train, and score machine learning models more efficiently.
Head of Data Science
Multinational Bank
Leading Multinational Bank
Head of Data Science
Multinational Bank
![]()
Gathr has brought all our data scientists on a single platform to design, train, and score machine learning models more efficiently.
![]()
Gathr plugs the middle layer to “hydrate our data lake from various systems – traditional, legacy, and mainframe alike.
Senior Manager, Data and Insights
Global Investment Company
Senior Manager, Data and Insights
Global Investment Company
![]()
Gathr plugs the middle layer to “hydrate our data lake from various systems – traditional, legacy, and mainframe alike.
EXPERT OPINION
Recognized by industry experts year after year
![]()
Gathr is a unified data platform that offers capabilities for ingestion, integration/ETL, streaming analytics, and machine learning. It offers strengths in usability, data connectors, tools, and extensibility.

![]()
The platform offers event stream processing capabilities.

![]()
Best big data analytics product or technology for real-time analytics.

![]()
Enterprises that need a unified data platform leveraging popular open source, big data technologies, accessible to business as well as technical users, must evaluate Gathr.

![]()
Gathr offers a wide range of solutions. It combines the strengths of open source with the reliability and support of an enterprise solution, in the cloud, and at scale, while also offering significant ease of use, integration, and SaaS capabilities among other things.

LEARNING AND INSIGHTS
Stay ahead of the curve

Webinar
Blog