BLOG
Key considerations for moving ETL workloads and enabling self-service ETL on cloud
The exponential growth of data across industries is fuelling the evolution of extract, transform, and load (ETL) processes. However, traditional on-premise environments are inadequate to support the ever-increasing data volumes due to high operational costs, rigid storage capacity, and limited infrastructure. The cloud, on the other hand, is fast transforming the way enterprises discover, mine, store, and analyze data.
By 2021, over 75% of mid-size and large organizations will have adopted a multi-cloud or hybrid IT strategy. – Gartner
Enterprises are increasingly moving their ETL workloads to the cloud to take advantage of its many benefits.
Some reasons why businesses are moving to the cloud are:
Elasticity
Unlike on-premise infrastructure that forms the backbone of traditional ETL storage, cloud technologies like S3 and Google Cloud Datastore are highly scalable and elastic
Agility
Serverless technologies and data processing frameworks make it possible to quickly assemble an ETL infrastructure in the cloud, while automated, demand-based compute provisioning makes ETL processes responsive and adaptive
Data archival cost
Most cloud providers offer low-cost storage services for data archiving. Players like AWS, Google Cloud Platform (GCP), and Azure also offer economical cold storage services
Resources cost
The cloud enables optimized resource planning and enhanced flexibility leveraging pay-as-you-go models and cost control tools
Performance
ETL on the cloud delivers better performance powered by scalability, elasticity, and easy access to newer hardware advancements
Maintenance
Cloud services require fewer maintenance cycles and lesser downtime
Despite these advantages, migrating ETL workloads to the cloud comes with a high risk of failure. Selecting the right partners, tools, and approach for the transformation can reduce the risks and ensure a seamless migration.
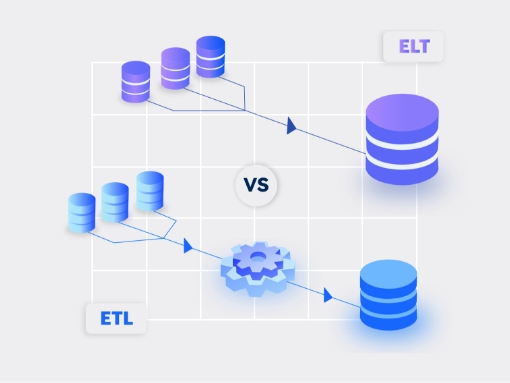
Choosing the right approach to migrate ETL workloads
Typically, application migration efforts fall into one of the two categories – ‘lift and shift’ or rearchitect. Lift and shift primarily focuses on migrating workloads ‘as-is’ to the cloud to leverage the elasticity that the cloud offers. On the other hand, rearchitecting involves redesigning the workloads by leveraging the service registry, ISV offers, and other technologies available in the cloud. We recommend considering an incremental approach, addressing lift and shift low-cost and low-impact isolated use cases first.
Some factors to consider while migrating ETL workloads to the cloud are:
1. Cloud vendor(s) selection
Adopt a vendor-agnostic approach to ensure multi-cloud support
2. Data migration tools
Build an incremental data ingestion process using tools that map on-premise storage solutions to cloud storage services
3. Workload/application migration
When redesigning an ETL process, focus on testability, rapid prototyping, processing infrastructure, and impact on upstream and downstream processes
4. Operationalizing ETL workloads on the cloud
Design for security, auditing, monitoring, SLA management, and lifecycle management
5. Structured framework approach to design
Ensure infrastructure portability, version management, workflow capabilities, reusability, separation of computing infrastructure, processing frameworks, and business logic
Choosing the right platform to run on-premise ETL jobs on the cloud
There are ready-to-use tools that allow you to migrate on-premise ETL jobs as-is to the cloud, without having to rebuild, thereby saving time, effort, and money. To ensure maximum business benefits, we recommend selecting a data-driven platform that brings together data access, transformation, machine learning, and all operational tasks. This helps create production-ready ETL pipelines from day one.
Look for a platform that offers a host of power-packed features such as:
Interoperability
Enables you to build once and deploy on any cloud like AWS, Databricks, Azure, Google Cloud, etc.
Hybrid
Allows you to connect on-premise resources with cloud resources
ETL operators
Offers a wide range of operators like deduplication, imputation, machine learning, and others that can be used on the cloud
Extensibility
Offers Python, Scala, and Java-based custom operators that can write customized codes, build, and test on-the-fly using data inspection
Vendor-agonistic
Ability to deploy the created pipelines on any cloud, leveraging a ‘build once and deploy anywhere’ approach
Monitoring and dashboards
Ability to monitor pipeline stats, performance, and create charts on real-time data
Deployment of pipelines
Ability to schedule pipelines to be run at a specific time/interval
Continuous development with pipeline inspection
Ability to test and debug a pipeline before deploying it on the cluster, along with a robust version management functionality
Gathr, as a data-to-outcome platform, offers all of the above and more. The platform enables easy creation of batch and streaming ETL pipelines that can be run directly on cloud (Databricks, Amazon ER, Azure, and Google Cloud) without the need to rewrite any code or recreate any application. It empowers users with complete control using easy-to-use drag-and-drop operators on a visual IDE canvas. Gathr has a wide array of built-in operators for data sources, transformations, machine learning, and data sinks.
To know more about how you can enable self-service ETL analytics, and machine learning on Gathr, start your risk-free trial of Gathr today.
Table of Contents
MEET GATHR

Turn raw data into business outcomes, at scale and 50x faster
-
Ingestion
-
ETL
-
CDC
-
DQM
-
ML
-
Insights
-
Atomation
-
Xops
-
Business Apps
Recent Posts
View more postsBlog

Blog

Blog

Blog