BLOG
5 must-haves in a modern data pipeline tool
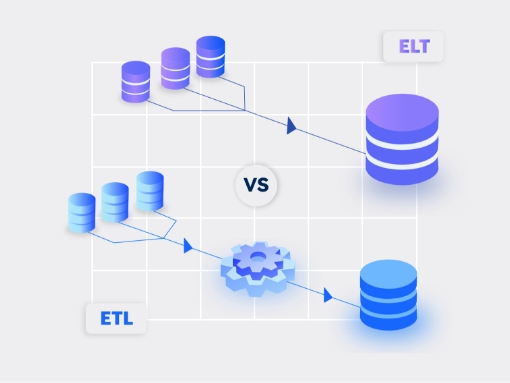
In the digital world, enterprises leverage data pipelines to move, transform, and store massive volumes of data. These pipelines form the backbone of business analytics and play a strategic role in enabling data-driven decision-making. Simple data pipeline use cases include ingesting data from multiple sources and delivering to a data warehouse/data lake on the cloud. More complex use cases involve building custom applications, training datasets for machine learning, and more. With datasets growing in size and complexity, modern data pipeline tools play a major role in helping enterprises reduce time to insight and gain a competitive advantage. Here’s our take on what to look for in a next-gen data pipeline platform:
Native connectors for popular sources and targets
Most companies need to load data from multiple data sources, including SaaS applications, streaming services, databases, spreadsheets, and even information scraped off the web. What’s more, the data comes in varied formats like JSON, CSV, AVRO, and Parquet. Your data pipeline tool should be equipped to handle all these formats and provide in-built, native connectors for all popular source and target platforms. The option for creating your own connectors and building parsers for custom sources/formats is an added advantage.
Simplified data integration capabilities
To create fully-loaded pipelines, enterprises need to ingest and integrate data on-the-fly from both batch and streaming sources. An ideal data pipeline platform should offer out-of-the-box capabilities to process high velocity data as it arrives, enabling users to customize, enrich and transform data even before it hits their data store. Look for a data pipeline platform that is easy-to-use and helps data teams create date integration pipelines in minutes without the need for hand-coding.
Self-service management
Most traditional data pipeline tools are not able to transform incoming data fast enough before loading it to the target warehouse or data lake. On the other hand, modern self-service tools provide built-in operators that allow users to easily transform data, leverage DataOps, and build, train, and deploy ML models at scale. Irrespective of skillsets, both technical and non-technical users can create, maintain, and monitor pipelines in a self-service manner.
Next-gen automation
Advanced automation capabilities in a pipeline tool can help data teams drastically save development time and effort. Look for platforms that auto-create schema, assign data types and populate timestamps, names, IP addresses etc. Automated data validation is another major value addition, as this helps instantly detect any mismatch between source and target data stores to keep your data accurate and trustworthy at all times.
Collaborative capabilities
To enable a single source of truth in the digital era, enterprises need to bring data engineering, data science, IT and business teams on the same platform. Next-gen data pipeline platforms can help multiple users collaborate seamlessly by providing reusable transformation templates that can be leveraged across ETL pipelines. Certain platforms also enable users to clone entire pipelines or use common saved entities, rules and processor groups to build similar applications. Such features help developers avoid repetitive tasks and improve productivity significantly.
To summarize, modernizing your data pipeline platform is no longer a choice, but a necessity. It can help you save development time, build analytics agility, and solve business use cases with greater ease. To discover how Gathr can help you realize these goals, start your free 14-day trial of the platform today.
Table of Contents
MEET GATHR

Turn raw data into business outcomes, at scale and 50x faster
-
Ingestion
-
ETL
-
CDC
-
DQM
-
ML
-
Insights
-
Atomation
-
Xops
-
Business Apps
Recent Posts
View more postsBlog

Blog

Blog

Blog