Customers
Trusted by the largest enterprises on the planet
Spotlight
Top Trending Stories






MEET GATHR
One-of-a-kind no-code, unified
data-to-outcome platform
- No-code for data at scale, batch and streaming
- Gen AI help to search, understand, query, and build easily
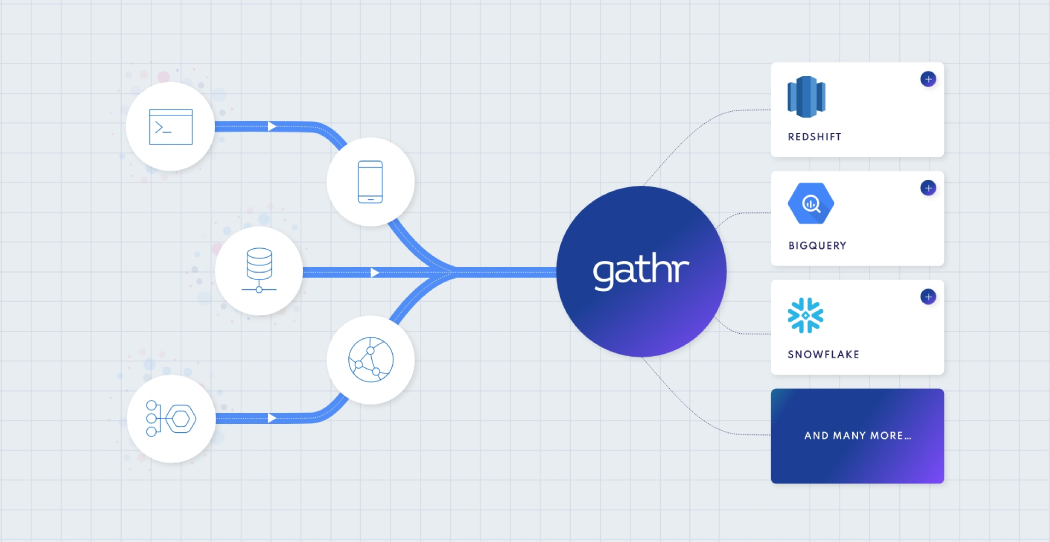
- 250+ connectors,
200+ operators,
50+ apps and
solution blueprints - Unified collaborative experience
- Best of open source and enterprise grade
- Production ready output from day 1
Capabilities
 Data integration
Data integration  Machine
Machine  Action
Action  Workflow & business process automation
Workflow & business process automation
 Business
Business 
Turn raw data into
business outcomes at scale & 50X faster
Gathr unifies data engineering, ML, Gen AI, analytics, and process automation over a single platform. The unified experience fosters seamless collaboration between teams, from experiments to launch. Moreover, with Gen AI assistance, and no-code rapid application development, Gathr boosts productivity significantly. Our customers have unlocked ground-breaking success with Gathr, from ingesting petabyte-scale data in real time, to orchestrating thousands of complex data pipelines within a few months, delivering in-the-moment actionable insights to everyone so they can multiply their business impact, and architecting enterprise-ready Gen AI solutions.


Turn raw data into
business outcomes at scale & 50X faster
Gathr unifies data engineering, ML, Gen AI, analytics, and process automation over a single platform. The unified experience fosters seamless collaboration between teams, from experiments to launch. Moreover, with Gen AI assistance, and no-code rapid application development, Gathr boosts productivity significantly. Our customers have unlocked ground-breaking success with Gathr, from ingesting petabyte-scale data in real time, to orchestrating thousands of complex data pipelines within a few months, delivering in-the-moment actionable insights to everyone so they can multiply their business impact, and architecting enterprise-ready Gen AI solutions.
Use Cases
What do customers use
Gathr for
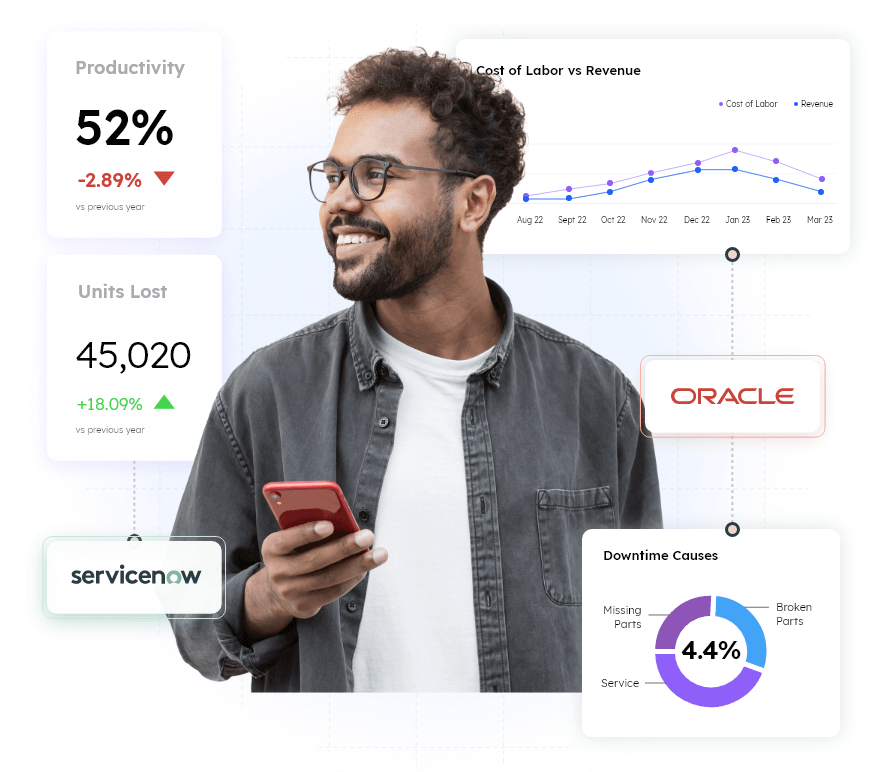
 Oracle cloud cost optimization
Oracle cloud cost optimization

 Lead quality
Lead quality
 Lead quality
Lead quality
 Sentiment analytics
Sentiment analytics

 Sentiment analytics
Sentiment analytics
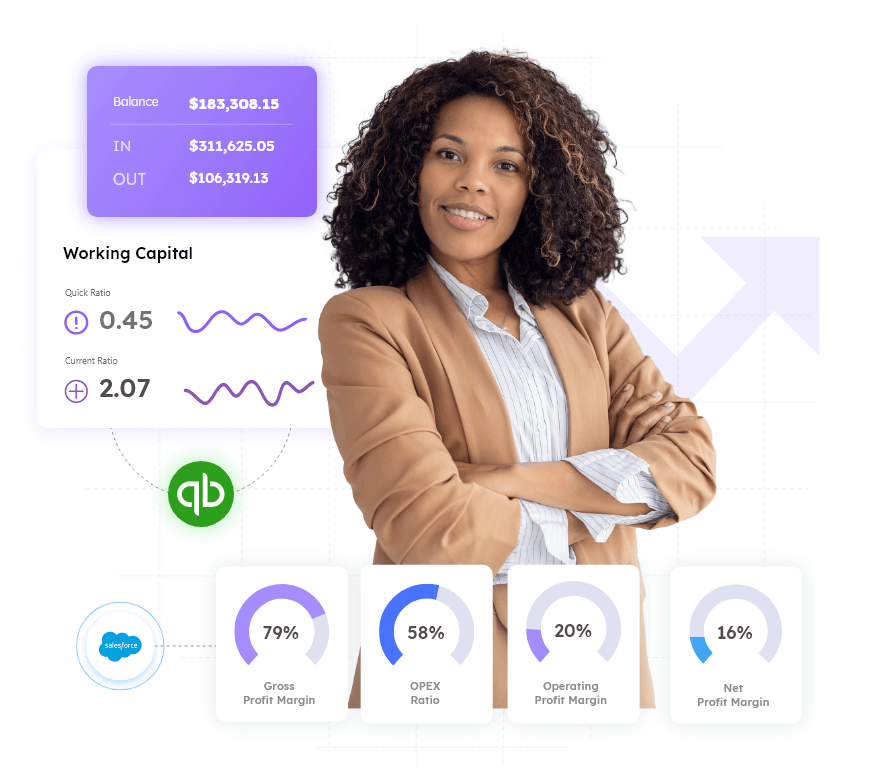
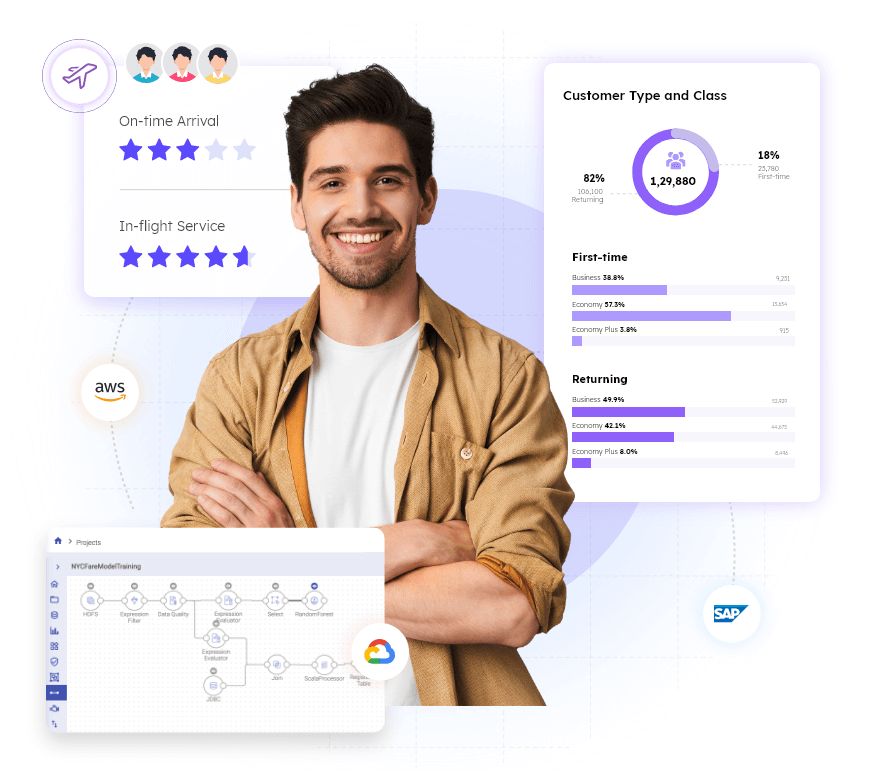
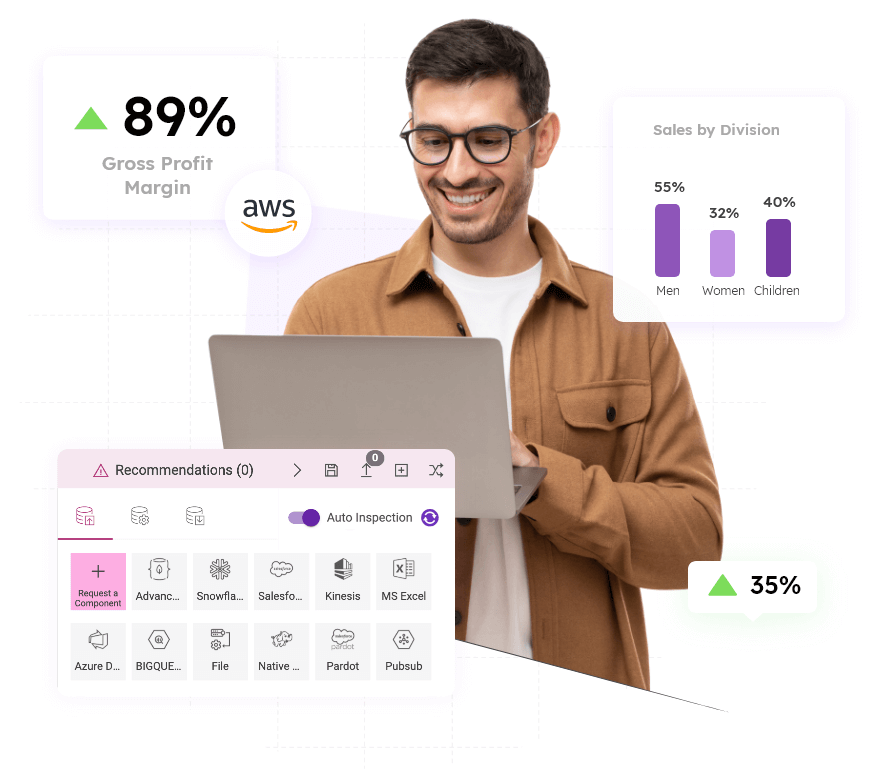
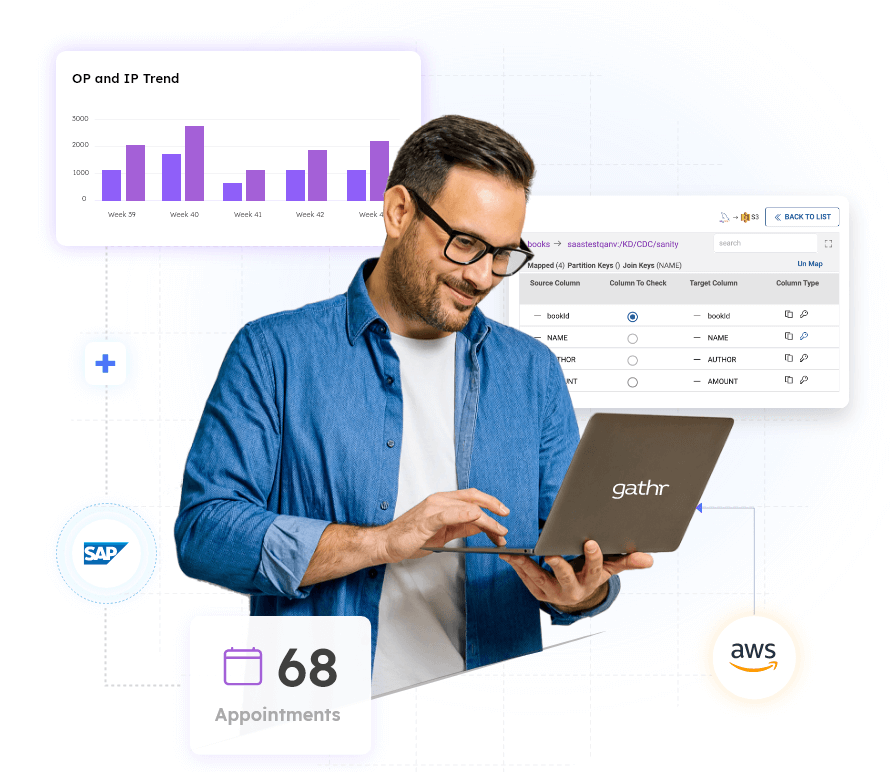
 Healthcare quality management
Healthcare quality management
Customers Speak
Trusted by business leaders
![]()
![]()
Gathr helped us power “in-the-moment” actionable insights from massive volumes of complex operational and digital interaction data.
Sarang Bapat
Director, Data Engineering Solutions and Delivery
![]()
Sarang Bapat
Director, Data Engineering Solutions and Delivery
![]()
Gathr helped us power “in-the-moment” actionable insights from massive volumes of complex operational and digital interaction data.
![]()
![]()
Gathr unlocked upselling, cross-selling, and customer retention use cases with speed and scale. We consolidated data sources, created self-service pipelines, and retired legacy platforms.
Shekar Dahiya
Software Engineering Director
![]()
Shekar Dahiya
Software Engineering Director
![]()
Gathr unlocked upselling, cross-selling, and customer retention use cases with speed and scale. We consolidated data sources, created self-service pipelines, and retired legacy platforms.

![]()
We went from 2 days to 20 minutes per quarter to compute our PI metrics with Gathr.
General Manager, ALM
General Manager, ALM
![]()
We went from 2 days to 20 minutes per quarter to compute our PI metrics with Gathr.
![]()
![]()
Gathr helped us replace 1.5M lines of code through its visual interface.
Prabhu Charan
Vice President of Engineering
![]()
Prabhu Charan
Vice President of Engineering
![]()
Gathr helped us replace 1.5M lines of code through its visual interface.

![]()
Gathr has brought all our data scientists on a single platform to design, train and score machine learning models more efficiently.
Head of Data Science
Head of Data Science
![]()
Gathr has brought all our data scientists on a single platform to design, train and score machine learning models more efficiently.
Expert Opinion
Recognized by industry experts year after year
![]()
Gathr is a unified data platform that offers capabilities for ingestion, integration/ETL, streaming analytics, and machine learning. It offers strengths in usability, data connectors, tools, and extensibility.

![]()
One of the key event stream processing platforms – offering exceptional real-time data processing and analytics capabilities.

![]()
Best big data analytics product or technology for real-time analytics.

![]()
Enterprises that need a unified data platform leveraging popular open source, big data technologies, accessible to business as well as technical users, must evaluate Gathr.

![]()
Gathr offers a wide range of solutions. It combines the strengths of open source with the reliability and support of an enterprise solution, in the cloud, and at scale, while also offering significant ease of use, integration, and SaaS capabilities among other things.

Customer Stories
Powering breakthrough success




Watch Gathr in action

Learning and Insights
Stay ahead of the curve