

BLOG
ETL vs ELT: Which data integration practice is right for you
ETL and ELT are common data integration practices that are extensively used in data science and business intelligence. While leading enterprises use both approaches, you might be wondering what is the difference between ETL and ELT?
Find out which data integration practice is right for you in this head-to-head ETL vs ELT comparison.
What is ETL?
ETL, which stands for Extract, Transform, and Load, is one of the most popular data integration and pipelining processes. In ETL, unstructured data is first extracted from its source and moved to a staging area. Once data is cleaned, validated, and made compatible with the new system, it is loaded into the target environment to gain analytical insights.
![]()
Key benefits of ETL
Stability
ETL is known for being a stable and fast solution that can cater to pre-defined use cases. Since data is already structured and transformed before loading, it leads to stable operations.
Compliance fulfillment
Additionally, the ETL process makes it easier to comply with standards like GDPR, HIPPA, and CCPA. This is due to the flexibility provided by ETL, as users can easily omit sensitive data before loading it to a target system.
When to use ETL?
In ETL, the extracted data is only loaded to the data warehouse from the processing server after it has been transformed. This makes it ideal for processing data sets that need extensive transformation or when you need to restrict loading specific data to the target environment. For instance, consider the example of Online Analytical Processing (OLAP) data warehouses, in which only relational SQL-based structures are accepted.
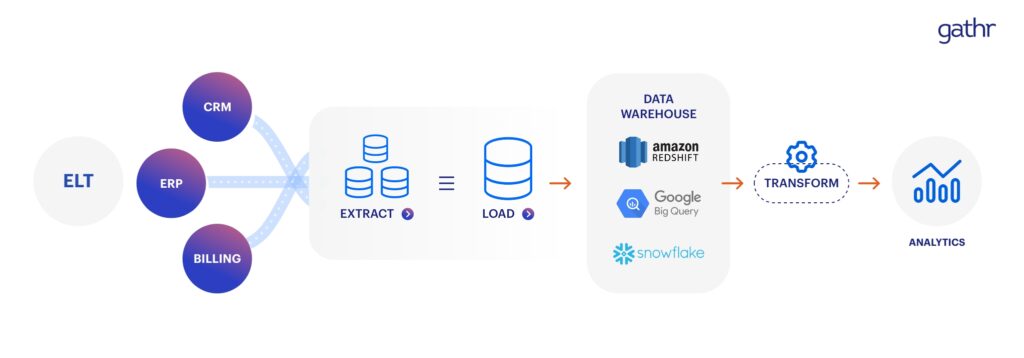
What is ELT?
Extract, Load, and Transform, commonly known as ELT, first pulls unstructured data from its source, loads it to the new system as-is, and then performs transformative operations.
In ELT, vital operations like data cleansing, transformation, and enrichment occur in the data warehouse, making it easier for users to make multiple transformations to the raw data.
ELT is a newer concept that has evolved due to scalable cloud-native warehouse support. For example, cloud-based data warehouses like Snowflake, Azure, and Redshift have provided the needed digital infrastructure for storing and transforming data faster.
Key benefits of ELT
Flexibility
ELT provides the flexibility to explore the entire data set (including real-time data) without overheads. This is because users can get all kinds of data analysis without loading additional data sets.
Easy of maintenance
Due to its robust appeal, ELT processes are easier to maintain and require lower fulfillment expenses. Modern ELT tools undertake automated cloud-based transformation, which further lowers the overall cost.
When to use ELT?
Since ELT can handle diverse data sets, it is mostly used for processing structured and unstructured data in large volumes. When data latency is a concern, ELT is mostly preferred as multiple transformational operations can be performed to obtain instant analytics. That’s why ELT is often implemented in a cloud-native environment that demands low maintenance and can perform frequent transformation operations efficiently.
What is the difference between ETL and ELT?
The key differences mainly lie in the sequence in which tasks are performed. Besides that, ETL and ELT processes also differ regarding the size and type of data they undertake.
With ELT, the process of loading data has been streamlined because there’s no staging area involved, which means that the data loads faster. In ETL, while it might take more time to load data, the output is cleaner and more organized.
Here’s a quick ETL vs ELT comparison to help you decide which process is right for you.
| ETL | ELT | |
|---|---|---|
| What is it? | Data is first extracted, then transformed into a processing server before loading to the target system | Once data is extracted from the source, it is loaded to the target system and then transformed in the target environment |
| Maturity | It has been around for 20+ years | It is a newer form of integration |
| Code-based transformation | In a secondary server (for heavy transformations) | In the database (simultaneous load and transformation) |
| Security and compliances | Better suited to meet security and compliance standards | Direct loading of data needs more security restrictions |
| Data output | Structured (in most cases) | Can be structured, unstructured, or semi-structured |
| Data volume | Ideal for data sets with heavy transformation needs | Good for large data sets that need speedy analysis |
| Data latency | Overall higher latency due to heavy transformation | ELT has a lower data latency in most cases |
| Target storage requirements | Low storage requirements (since only the transformed data is loaded) | High capacity is needed to store and process data |
| Maintenance | Continuous maintenance is needed | Lower maintenance is required |
| Implementation | On-premises or on the cloud | Ideal for cloud data warehouses |
| When to use? | ETL is suited to process data, complying with GDPR, HIPAA, CPA, and other standards. It is ideal for data sets that need heavy transformation and more stability. | ELT follows a more flexible approach and is ideal for a cloud EDW. It is best suited to meet frequent analytical needs and reduce time to insights, where following security compliances is not a primary concern. |
ETL vs ELT: Bottom Line
The choice between ETL and ELT boils down to factors such as the available data sources and formats, the target destination, data volume, processing and latency requirements, and your overall infrastructure.
Both techniques can help you cater to your data integration needs in different ways. Apart from your existing technical stack, you should also consider your long-term business plans while picking a preferred approach.
Transform with Gathr!
Legacy ETL/ELT platforms can suffer from various challenges. For instance, most legacy tools are costly, non-flexible, and non-scalable. They also have limited transformation potential.
That’s why enterprises are switching to a unified data pipelining platform like Gathr that can meet all engineering and integration needs in one place. The self-serve, no-code data pipeline platform can create batch and streaming ETL pipelines with drag-and-drop actions. Apart from ETL, ELT, and reverse ETL, Gathr’s power-packed features can also help you with Change Data Capture (CDC), data ingestion, streaming analytics, data preparation, and so much more.
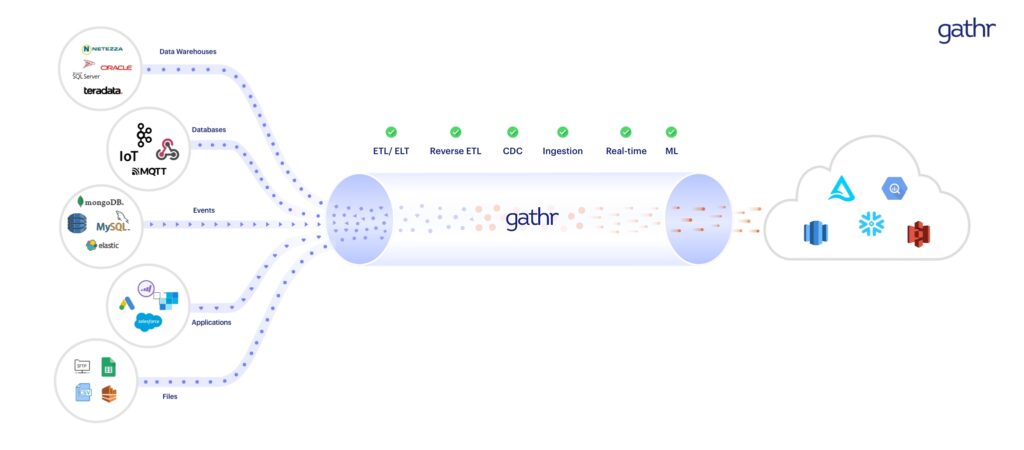
Explore Gathr’s multiple deployment options and start your 14-day free trial to begin your data transformation journey today.

Table of Contents
MEET GATHR

Turn raw data into business outcomes, at scale and 50x faster
-
Ingestion
-
ETL
-
CDC
-
DQM
-
ML
-
Insights
-
Atomation
-
Xops
-
Business Apps
Recent Posts
View more postsBlog

Blog

Blog

Blog
